一,前言
我记得吴博士说过,科学决策,有四个要点,分别如下:
1,所有的决策,要有数据来做支撑。
2,不要用结果好坏来评判决策
3,要不断地去复盘整个经过,细节,找到可以优化的点
4,要克服自利性偏差。
而这篇文章,要解决的就是如何获取数据的问题。
如果你像我以前做电商时,分析大盘的数据,去统计竞争对手的用户评价,用的是手工复制到excel当中去。
或者你想要某个大V公众号的文章内容,像我复制魔王波旬公众号的文章,是一页一页复制到word中,然后保存,花了几个小时也才保存100多篇文章。
或者像我群里面的红蛙老师一样,做餐饮的调研,也是手动去知乎把用户关心的问题给摘录到excel当中去。
那么为了提高效率,节省时间,你们都应当看下这篇文章。
顺带说一句,我也是刚通过一个大佬的课程,学会了如何抓取数据的,花了大概2个小时的时间。
二,为什么要使用爬虫插件去获取数据?
因为人们在互联网上的搜索,提问,关注,赞同,评论,一旦样本量足够大,就比较难作假,可以给我们去做用户调研,去洞察用户是怎么想的提供证据。
举例来说,我老婆现在进了一些耳环耳钉的货,她自己敏思苦想,想在抖音上说点什么好,那么除了在抖音搜索相关的同行,看同行怎么说,也可以去知乎看下喜欢饰品的小姐姐们,都提了些什么样的问题,回答的人,喜欢数都达到了多少,越是喜欢的人越多,证明这个受众就越广泛。
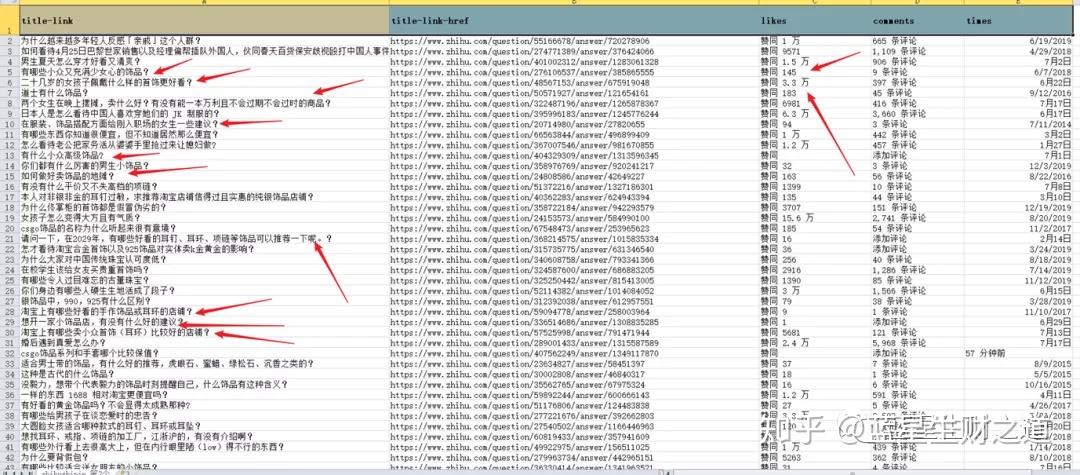
而且我今天用爬虫抓取到数据,光是看标题,就能让你对用户画像有个大概的猜想,你就知道你的耳环饰品是卖给谁的,她们想要些什么样的东西。
三,如何爬取数据?
先决条件,你得需要安装谷歌浏览器以及webscraper插件。
学习整个操作过程,大概是1个小时就足够了。
明白老师是花了21节课来讲这个爬虫插件webscraper如何使用,我是以2倍语速看完,其实还是相当简单的。
应当说任何人都能够学会这个爬虫插件的使用,官方的操作文档在这个网址,webscraper官方操作文档
https://webscraper.io/documentation
。
webscraper提供了十几种选择器,供我们去抓取不同类型的数据。
在网页上的数据,一般就是文字,图片,超链接,以及块状元素,这些有些基础的都听得懂的。
然后这个插件也是提供了这些选择器供我们去使用。
我录制了一小段视频,大家可以看下。其他的操作都是大同小异的。
关键就是要搞清楚你到底想获得什么样的数据,是单一维度的数据,还是多维度的数据,多维度的数据,就要用到element这个选择器。
四,数据清洗之后的结论才是最后一步
拿到同行的数据,同行详情页的评论,你要通过排序,筛选,清洗掉无意义的数据,去得出对你想要做的事情有帮助的一个数据才是至关重要的。
比如我老婆现在在卖饰品,如果我想去知乎回答引流,那么我会设置一个点赞的标准,点赞数太少的,没必要看,点赞数很多的,我只能看下他们的行文逻辑,不能去这个问题下回答,因为已经被他把这个话题占据了。
如果是做淘宝的,想要挖掘用户需求,就得看下评论里面高频出现的,是什么词,针对这个词,再去看自己的产品是否能解决问题。
PS,如果想获得明白老师的完整的讲解视频课程,可以后台回复【明白】。