近两年在国产通用计算和图形GPU领域诞生了多个初创IP,看似百家争鸣的局面;正式商业流通的有景嘉微,已经流片验证但尚未预订投片产能的有芯动、摩尔线程、壁仞、航锦等;此外还有一批IDC算力卡,如登临、燧原、沐曦、天数智芯等等;同时国家队参与的还有兆芯、中船重工709所/716所等等。其中各家图形产品的商业化定位普遍在桌面PC和低端信创服务器的搭载,一则存在设计成熟度和workload的局限,二则该市场当然也代表着出货量最大的SKU。本篇简要谈谈这些通用计算+图形产品的IP传承、市场定位和技术生态话题;但暂不谈算力卡。
首先对于某家桌面卡,虽然不用关注跑分,但实现通用产品也很不容易:Graphics+SIMT+Tensor+软件栈,这个工程量其实很大的,任意一个子项单独开发都难以19个月完工交图;研发成本更不会这么低(想想Palladium工具每套单价…FYR);以及与DirectX/OpenGL/Vulkan等API适配也不会这么顺利;因此解读如下:
某厂Spec:2048个MUSA核心,单精度6TFLOPS,8GB显存…,支持很多种Frameworks/APIs;团队商业化意图挺快和明确的,目标市场是信创台机+云桌面吧;
关于外购IP和设计服务:
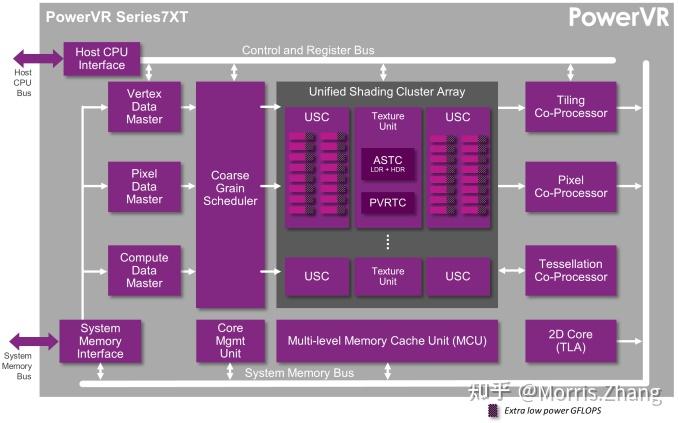
业内大致认识是:其licensed Imagination完整的hard IP core+design NRE,联创的团队并没有时间参与完整design,大部还是IMG的工程管理(得益于IMG的物美价廉的IP库和授权政策);
国内的几个做通用GPU/图形卡的startup,基本都依赖成熟IP House的工具箱和设计服务;要么是有正规渠道去获得ARM Mali的Architectural license;要么可以选择走中低性能路线的VeriSilicon/Vivante license;要么是计算低配但图形有优势的Imagination license;上述的后两厂甚至已经把startup ecosystem作为主力营销方向了。除此三者以外,还有继承了ATI老牌背景的景嘉微,也是主打信创桌面和中低端服务器的通用GPU(独立卡);以及继承了VIA+S3宝藏遗产并承担着国家核高基1号专项的兆芯(集成核显+独立卡)。
虽然外购IP+Design service看似是讨巧的商业,核心电路专利不能自控和自主迭代,但却十分有利于商业变现,可以快速获得成熟系统和后端版图,可以快速构建软件栈和底层工业API适配,可以快速流片量产,于是极大降低了研发周期和风险;换句话讲“谁会从零开始画电路呢”。诸如Huawei和Apple也使用外购IP,但却有一点不同的是,两者都是习惯在架构许可的基础上投入大量自研,在专精电路、芯片构型、系统集成以及数学库/软件栈/工具链方面加入了更多定制,最终产品就是半个自研核,随之生态也会自建。
因此,即不能轻视外购IP的商业模式,也不能轻易的自称自研。
关于应用场景和市场定位 - Cloud Compute
基于Spec推测几家startup的产品应该主要应用在信创PC和云桌面方向;设想倘若部署在Cloud IDC场景里,那么对于机架的面积效率而言会比较尴尬,机架占用的经济性并不高,计算低配,图形短脚,并联Pod的效率和弹性也不高。这就反思Nvidia的优势了,虽然全球很多厂商都有强于A100和DGX的算力,但却无法轻易替代拥有通用计算+图形渲染的TCO恐怖平衡的NV卡,同一个机架的多任务和面效比极高;因此,尤其对于Cloud IDC客户而言,其更加在乎的还是经济性/TCO,就连AWS的Inferentia机型保有量也没敢上架太多。所以,当前Spec在信创桌面场景会有更好的发展,比如跟飞腾适配主板,应用层花时间兼容一下信创名录。虽然IMG IP做PC显卡会有点累。
关于应用场景和市场定位 - Cloud Gaming
Cloud Gaming是CSP显性的技改趋势,当下普遍是在互联网企业的私有云形态上,professional rendering通常还是在workstation形态,gaming大部都是client;所以AIDC其实对于图形的要求目前还看不见;比如类比商汤的AIDC大装置,在那幅公开的图示里也没有graphics模块;因为目前graphics的确不在公有云的需求里面。对于Cloud IDC来讲,为了一个远期趋势/热点,而提前布置机型是不划算的,所以基本没有云端渲染机型,即使有,那也是Facebook/Meta的前卫场景。
相比之下,腾讯的游戏部门也在设计Cloud Gaming,他们需要ARM based Cloud env,关键需求是跟移动终端联动,但目前还是在私有云环境中。众所周知,手机端就是兼容主流的ARM系统,GPU方面主要就是QCom Adreno兼容ARM驱动(Mali的渲染能力不谈),但据传腾讯团队现在基于AMD Radeon RX6000(可以支持ARM驱动)......
当然还有Imagination,毕竟苹果licensed了这颗GPUcore多年;但冒然的讲,IMG的真正实力还是在移动端,毕竟延迟贴图渲染(TBR/TBDR)的移动端和实时渲染(IMR)的桌面端的架构完全不同,Mali和Adreno都是TBR,而IMG PowerVR的特点就是TBDR(节省带宽开销,做到零overdraw)。AMD在统一渲染方向探索了多年也未成行,其中一些benchmark显示能效比相差悬殊。话说回来,前面提到Gaming的场景更多是在client,所以其实IMG的硬件光追更加派上用场了:)。当下只是想象不出为什么IMG core没有进入安卓机市场,也许是苹果的竞业禁止?但猜测应该过期了吧?
关于流片与量产 - 风险与经济性
虽然外购IP+Design service的模式帮助系统快速定型,甚至后端图版也会帮你做好;但仍需要重视规模化量产的风险:推测没错的话,16核或32核以上的IMG IP的芯片,至少在TSMC没有大规模验证过,首个交付量产的厂商多少会承担一定风险。
以及要考虑成本和经济性,举一个我经手的例子(于2018-20年操作的项目,数据放到现在可能不准):1TFLOP的AMD 3代前产品,批发价约$17美金,2020年中涨价到$25左右,这才多大的TAM呢?那么算一笔账,假设新产品用TSMC 12nm工艺,流片出来成本约$25,必须卖出$40+才能摊薄前期研发和掩模费用,… 卖给谁?而且是百万级的出货量才有这个价格;所以自己算吧,12吋7w平,1TFLOP可以做到50-60平,良率算50%,基材成本大约$6000刀,掩模那些不算,加流片加工费,再加TSMC 50%毛利要求,以及TSMC前年公布把3% discount免除了;那么这个量产的经济模型就不容易计算盈利面了;况且还有服务和销售费用。
摘录媒体:Apple和Imagination在2020年的GPU出货量均实现了两位数增长;Apple于2017年转向内部GPU,其iPhone和iPad GPU出货量强劲。联发科的大出货量Helio的4G芯片中也采用IMG IP,也让后者同比增长了23%,甚至挑战了ARM GPU份额。
下游的IP保护伞和生态依存:
除了IMG,VeriSiicon/Vivante也有几个授权厂商在业内,如景嘉微、登临等都有芯原IP。芯原Vivante IP的水平中下,FP16成熟,FP32这批新型号也有提升(国内空军采用了)。值得一提的是,登临的李老板就是Vivante的前CTO。再者是景嘉微,去年已然流了1Mu库存了,长城下的订单,随后就需要招募庞大的软件团队(应是硬件团队的2-3倍规模),开发图形库和并行计算;其实在Gaming以外的桌面用途是满足了。
无论初创公司或是成熟厂商,选择外购授权的另一原因是IP保护伞。比如IMG当下卖的保护伞,就是不论你用不用得上,能保障tape out的阶段顺利通过IP Audit即可;基于合法授权的免责效力,代工厂也没功夫去逐一核查几亿门电路。当然,有些RTL还是不能乱抄的,譬如Mali的那些,TSMC不要太熟…就好比论文查重,某司一年前就卡在这上面,ARM不给license,而手上私改的Mali G71/72倘若拿去代工厂流片,必然面临诉讼风险。
而都基于一家IP做保护伞的话,那么就需要两个因素了:一方面IP House放开Archi_License任由自己的IP碎片化,未来管理失控可能会像MIPS一样收不回授权费;另一方面,国内几家startup也需要有独道的手艺可以改出来指标至极的半自研IP,且保持自行迭代。但后者其实是比较悲观的,graphics基本改不出来,因为全球主流市场的API和驱动已经成熟数年了,反向锁死了硬核的专利墙,另辟蹊径的可能性不大了;况且graphics是独立专业领域,并不是几个EE/CS工程师游勇可以跨领域研究的。
如今国内Top-10的通用计算+图形GPU创业公司,几乎半数使用IMG IP,尤其芯动、摩尔线程、壁仞…等等top startup,推动了IMG生态大爆发;然而各家的硬件规格差别不大,比拼软件和应用适配性就成为角逐地了;这些都得益于IMG的物美价廉的IP库和授权政策(传闻IMG授权费$20m per license?求证);此外,IMG如今毕竟是国资委的资产,自主可控相比ARM Mali的血统更正(核高基明确过双A不是自主可控)。
以及商业化方面:GPU毕竟仅是单一处理器系统,尚且需要整机、应用和工具链的产业合作方,并非是startup可以独立衔接和协同的,这其中就再次的体现出IMG的双创惠民政策了,比如机型要求支持游戏用户,则提供适配DirectX/GL/Vulkan(版本受限),并适度调优之;使用IMG的全家桶可以事半功倍,它早已为自家核心打通了各种合作和适配。
再者,即使促成了整机型合作,PC这类产品毕竟是commodity,除非有强援支持集采,否则这种Spec的机型零售/渠道很难出货。
结语:
最后,信创市场不能轻视,其TAM空间足够广阔,粗略估计也要有50Mu+的;所以我想说的是,通用GPU,3年内没个10Mu订单不容易生存,而多数做算力卡的,可能永远靠包养。

Q&A
- 有人私信建议国产图形GPU自研核可以考虑反向工程“把底层APIs反向映射成门电路”。- 我其实没太理解,但强答一下:纵观Vulkan也是基于NV和AMD生态在推进(对于math_libs/硬件驱动和指令/API/甚至算子算法的谨慎适配),码农即使拿到偏向底层的代码,也是API相关的源码部分,当然不能映射/倒推到晶体管门电路设计的;而且诸如CUDA/Vulkan未公开的私有库如何反编译呢?对于编程人员,你只能拿API当指令集看,当然也可以钻研拿到一条指令后借此反推下面的RTL代码逻辑,琢磨怎么在门电路层面实现它,进而改出来一些私有库和专精电路,再对外广泛授权和自建生态...。但这些是空想,DX/GL/CL工业标准已经迭代了20年,其反向路径早给大厂的专利墙堵死了,在反工程基础上修改设计是绕不开的,特别是一些隐含算法,如shading那样的渲染子集,实现路径早给注册掉了。想想Apple花费多少代价支持GL社区才最终衍生出自主生态的Metal。
- 另外,现实中其实拿着库和API代码是推导不出完整RTL的,只能勉强推出这些库的电路设计理念,就算是开源了RTL代码,源码也只能意味着开放到RTL层面,也就是说我们只能看到这个处理器的微结构和逻辑如何实现,但是电路层、物理层乃至与工艺的对接我们都是看不到的;拿着这套源码最多也只能在FPGA上烧出一个功能相同但是性能差距甚大的GPU,想要全盘反工程复制,距离还是有些遥远的,并且源码中附带的工具脚本等可能都已过期过时,加上全芯片中并不是每一个模块的代码都是为FPGA综合所写,所以就连FPGA全芯片综合都要费一番功夫。况且图形方面硬件编译国内也没几个人。- 当然,作为工业标准的OpenCL/GL都有完整手册的,初创自研的GPU电路实现自然与NV不同,但API调用可以完全相同的,让前端用户/开发者降低使用门槛;比如天数智芯当前产品就是完美打包CUDA,基本不再开发私有软件栈。但倘若遇到CL/GL/DX标准库不够用的情况,那么就是两套方案:
::A 方案是可以与大厂合作(芯片出货量普及的话),比如微软合作,由其支持一套DirectX的外延库,生态就打开了;事实上,NV早期就是这种做法,如今却反逼的DirectX又免费又上云的(以及Unity似乎也是这个套路);前提是芯片出货量和SKU大了,场景用途和认可度高了,寻求DirectX和Vulkan联创合作有依据(OpenGL有苹果干预可能难点);但对于那些并没有出货量和独道场景,仅基于外购IP来发布产品的厂商而言,此路就不通了,比如基于IMG core,DX或可以支持到v9?OpenGL版本或是直接支持到v3.3或是其Linux下GL驱动走的还是Mesa Zink低效方案(即GL-over-VLK,在Vulkan的硬件驱动兼容层之上支持GL,最多3.x版本;Zink毕竟是驱动上嵌套一层,自己基本没法优化和迭代) 。这些都依赖IMG交付代码,即谈不上与原厂合作,更谈不上自改专精了,只能follow IMG update;
::B 方案是,若只是普通训练/推理任务,底层对私有库的要求不多,OpenCL标准库和API都能直接用,但倘若是设计一些变态大并行/大异构,或是高级图形渲染任务,那就需要独道了,非得私有库才能发挥出最独道的性能;那么,就要自研私有库+调用API+生态推广了(反观以算力卡为例,平头哥打法有阿里云站台,燧原类似打法有腾讯云站台,这都是先发优势)。