SQLite 是一个非常轻量级的嵌入式数据库,并且已经广泛使用在手机、电脑、浏览器等各种设备中。不过,SQLite 原本的定位是快速的在线事务处理 (online transaction processing - OLTP),其主要的执行设计基于行,存储设计基于 B-tree。然而,近年来随着数据分析的愈发流行,对在线分析处理 (online analytical process - OLAP) 的需求也越来越强烈。那么,原本为了 OLTP 设计的 SQLite 可以直接用于 OLAP 的场景吗?如果不能的话,差距是多大,我们又可以做哪些方面的改进呢?今天,我们就来聊聊发表在 VDLB 2022 上的一篇论文:SQLite: Past, Present, and Future.
SQLite: Past, Present, and Future 阅读笔记
看论文标题,我们就能知道这篇论文大概是讲 SQLite 的过去、现在、和将来的。首先作者们对 SQLite 做了一系列历史性的回顾和对现在功能架构的介绍。SQLite的主要优势有
- 跨平台 (Cross-platform)。SQLite 本身存储在一个单独文件中,所以可以很容易的在各个平台上使用。
- 简洁和自我包含 (Compact and self-contained)。SQLite 本身只是一个文件,也没有任何其他的依赖。
- 可靠 (Reliable)。SQLite 中的每一行代码都有超过600行代码来测试。
- 快速 (Fast)。SQLite 可以支持每秒上万次的事务处理。
由于 SQLite 设计用于 OLTP 的场景,SQLite 使用了基于行的存储结构,也就是说对于一行的所有列都是存储在相邻的内存结构中。SQLite 的算子也是基于行 (row-oriented) 的,并没有使用常用于 OLAP 的向量化计算。为了适用于 OLTP,SQLite 提供了 ACID 支持。而 ACID 在 OLAP 场景中一般是不需要的。
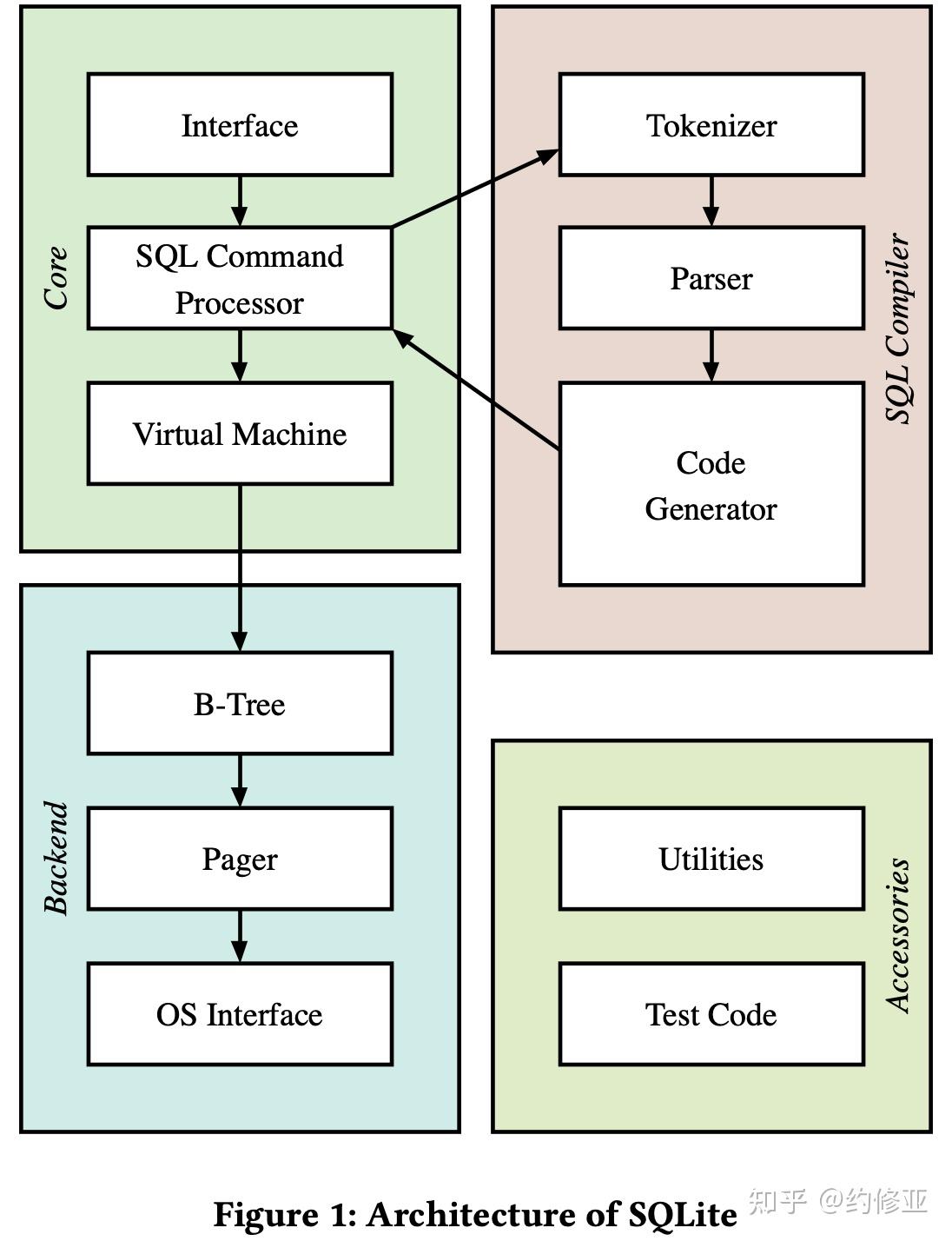
SQLite的整体架构如上图所示。Core 模块负责注入和执行 SQL 语句。SQL Compiler 模块把 SQL 语句翻译成可以在虚拟机中执行的字节码程序。Backend 模块和操作系统交互来实现数据的存储和页的使用。Accessories 模块则包含了诸如内存分配、字符串操作、测试等等各种辅助功能。
SQLite 对事务的支持有两种模式:
- 回滚模式 (Rollback mode)。在事务处理中,SQLite 把原本的页写入到回滚日志中并且把修改的页写入到数据库文件中。该模式同时支持 DELETE 和 TRUNCATE 两种子模式。
- 预写式日志模式 (Write-ahead log mode)。在事务处理中,不修改原本的页而是把修改的页追加写到单独的预写式日志文件中。
预写式日志模式可以支持更高的并发度并且常常有更好的性能。但是相较于回滚模式,预写式日志模式不能用于网络文件系统并会增加整体文件管理的复杂度。
说了这么多SQLite的优势,那么SQLite可以直接用于OLAP的场景吗?会有多少的性能劣势呢?论文中,作者们比较了SQLite 和 DuckDB (昵称 SQLite for analytics) 在 OLTP、OLAP、和 blob I/O 三个场景下的性能,并比较了它们的资源消耗。
1 OLTP
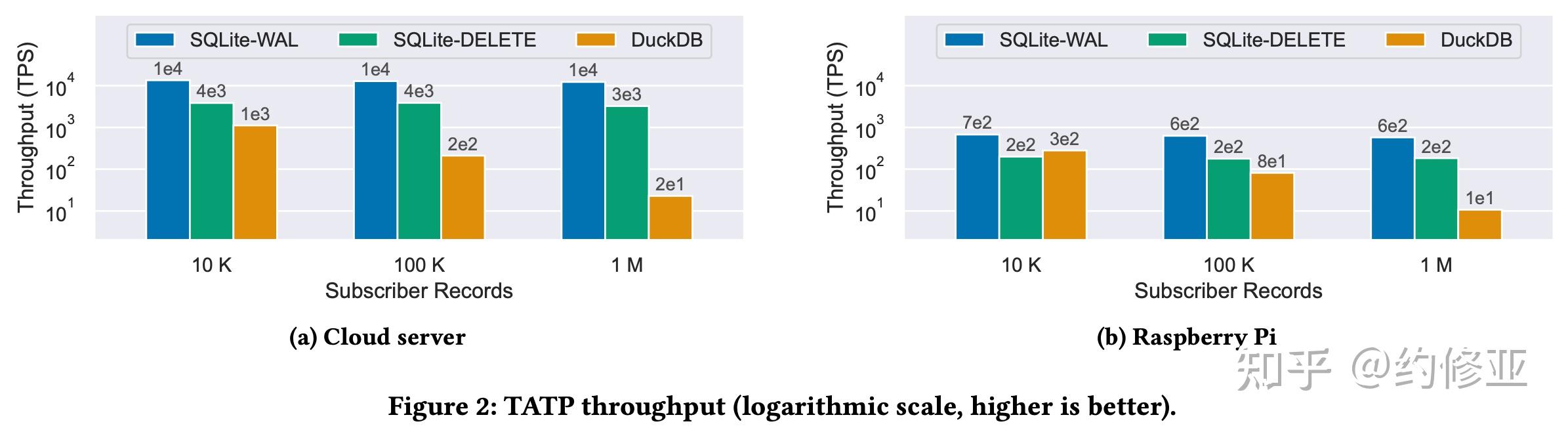
首先,作者们用 TATP benchmark 比较了 SQLite-WAL、SQLITE-DELETE、和 DuckDB 在 OLTP 场景下的性能。结果如下图所示。可以看出,无论是云服务器还是树莓派,SQLite 在 OLTP 场景下性能都显著的优于 DuckDB。当然这也是可以预见的,毕竟 SQLite 就是为了 OLTP 场景设计的,而 DuckDB 则是为了 OLAP。
2 OLAP
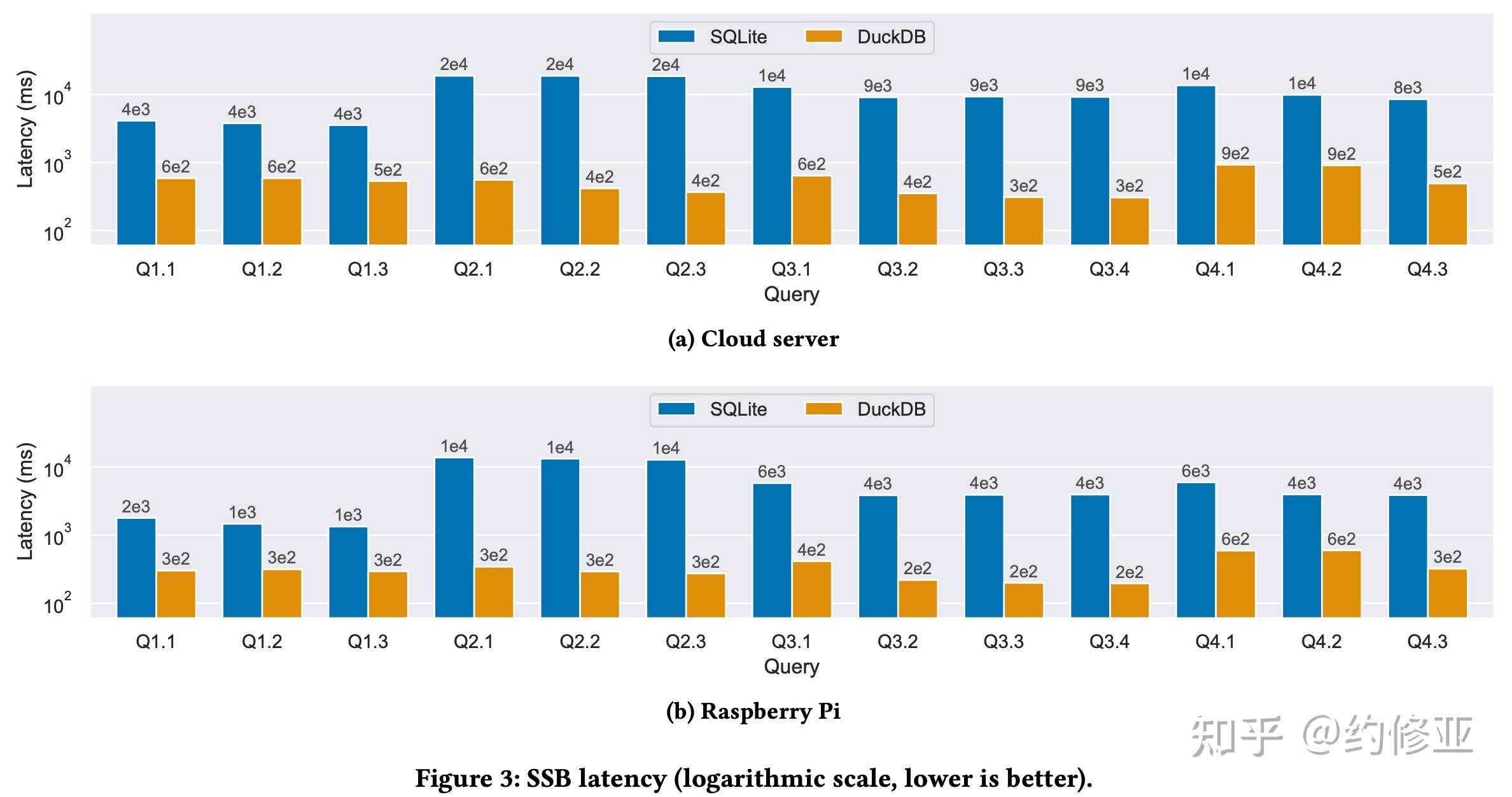
那么在 OLAP 的场景下呢?SQLite 和 DuckDB 分别表现又如何呢?下图是在 SSB 测试集下的结果。从图中可以看出,DuckDB 对数据分析型查询的性能要远优于 SQLite。当然,类似于上面的 OLTP 场景下的对比,这个结果也是可以预见的。毕竟 SQLite 的设计并不是为了大规模的数据查询。
既然 SQLite 在 OLAP下表现不佳,那么有没有什么方法能帮助我们改善呢?SQLite 对于 OLAP 场景的性能瓶颈又在哪里呢?论文中,作者们对查询的执行进行了性能剖析,发现了 SeekRowid 和 Column 两个指令花费了绝大部分时间。SeekRowid 指令用于搜索一个给定 row ID 的对应 B-tree 索引。Column 指令用于提取给定行中的具体某一列。针对这两个性能瓶颈,作者们提出了两种优化方法:
- 避免无谓的 B-tree 查询 (Avoiding unnecessary B-tree probes)
- 流水线化值的提取 (Streamlining value extraction)
对于第一种方法,作者们使用了一个布隆过滤器 (Bloom filter) 来首先判断给定的一个键值是否在列中存在。比如下图就是一个例子。

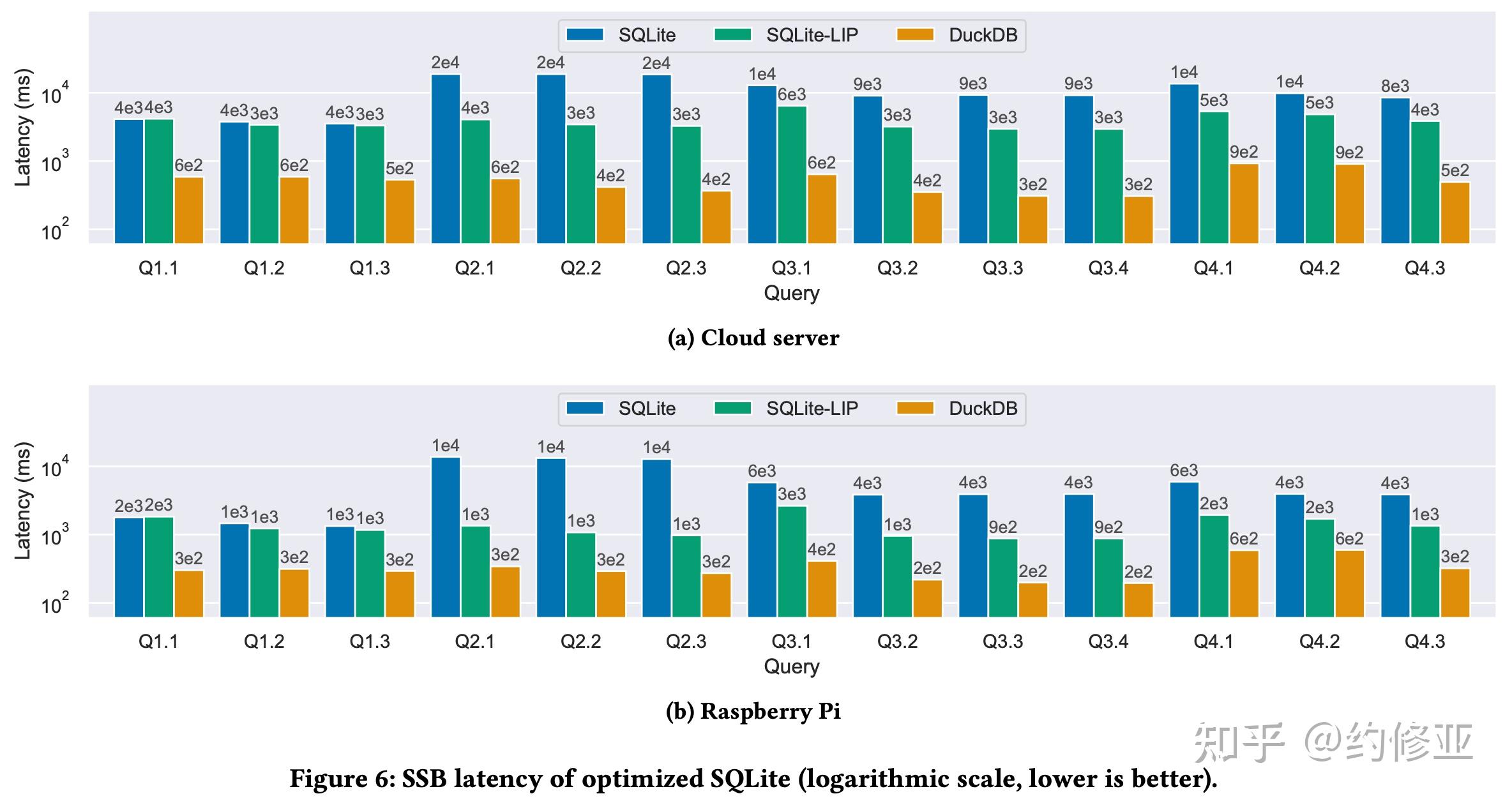
具体的实现方法是作者们在 SQLite 的虚拟指令集中增加了两个新的指令:FilterAdd 和 Filter。 FilterAdd 计算哈希值并在布隆过滤器中设置相应的位 (bit)。Filter 指令计算哈希值并在布隆过滤器中检查对应的位是不是已经被设置了。作者们发现仅仅是这样一个简单的优化就给 SQLite 在 OLAP 场景下的性能带来了巨大的飞跃,如下图所示。
那么对于第二种方法流水线化值的提取呢?这种方法效果又如何呢?SQLite 使用了灵活的数据类型,换言之除了主键必须是整数之外,其他任何数据都不需要是固定类型的,也不需要提前指定类型。基于这种设计方式,去提取一个值,SQLite 必须先得到一个指向被编码的值的指针。这种设计方法使得作者们很难流水线化值的提取,并且作者们在探索中也发现这种流水线化值的提取需要修改 SQLite 中的文件存储格式使之易于向量化。最终,作者们并没有实现这种方法。
3 Blob I/O
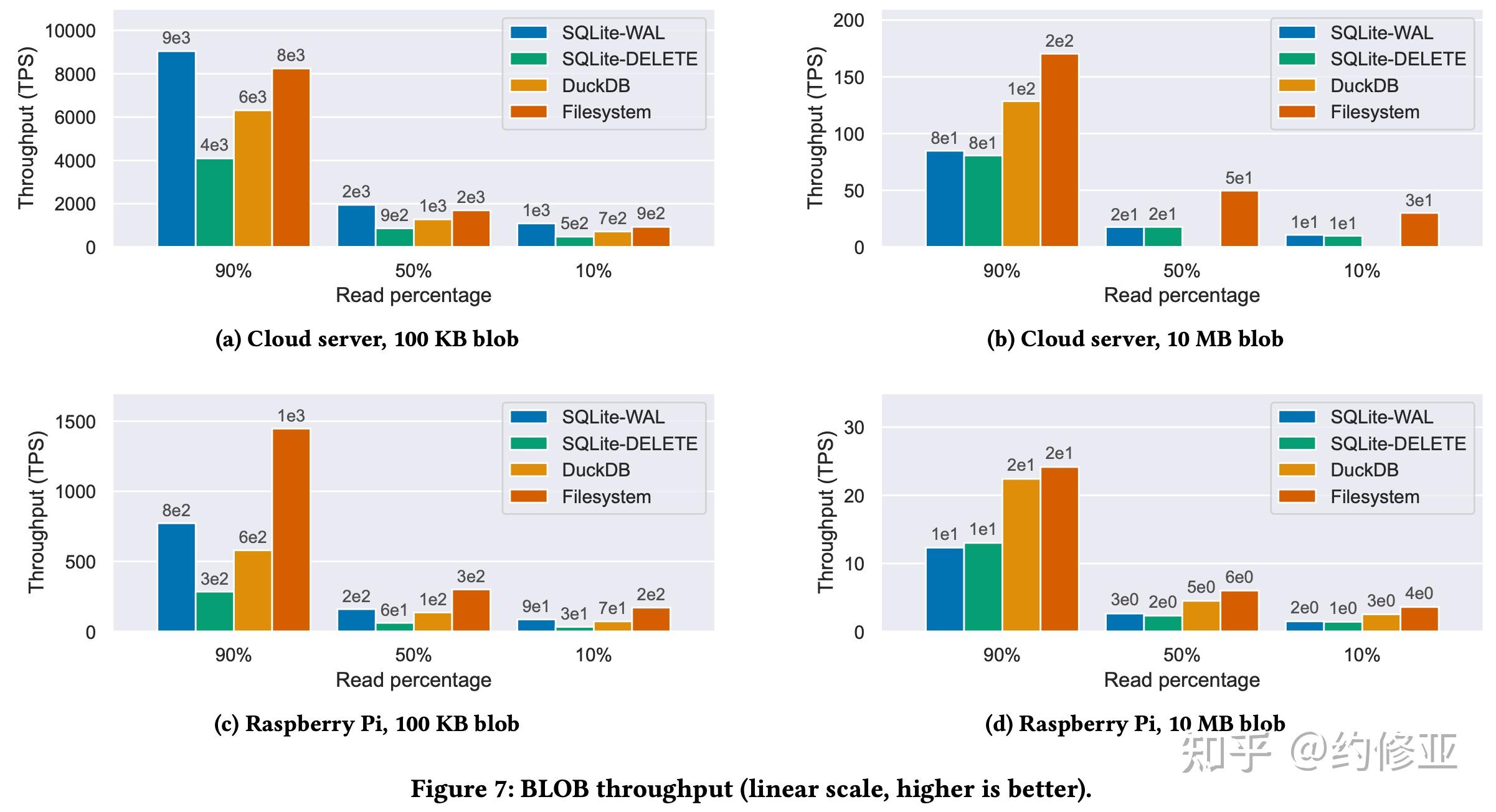
文章作者们发现 SQLite 在业界也常用于块数据的存储 (blob data store)。那么 blob 类型的数据对 SQLite、DuckDB、和文件系统有多少性能的差异呢?他们特别开发了一个基于 blob 数据的测试集。这个测试集提供了不同比例的读写操作。总体来看,在云服务器上,SQLite-WAL 模式可以获得比较好的性能。而在树莓派上,DuckDB 有比 SQLite-WAL 类似或略好的性能。
4 资源消耗
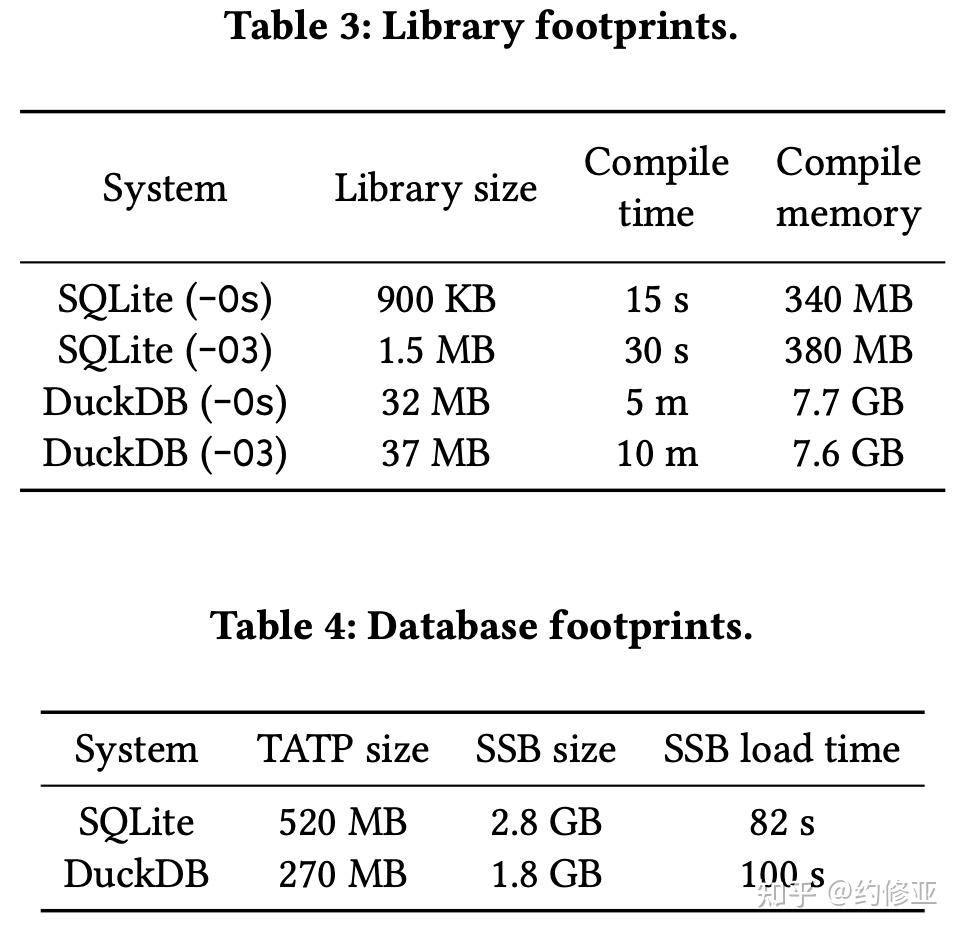
作者们比较的最后一个维度是资源的消耗 (Resource footprint)。总体来看,SQLite 需要更少的资源去编译,而 DuckDB 需要更少的空间来存储数据 (主要因为采用列式存储易于压缩)。
这篇文章回顾了 SQLite 的设计、开发、以及在实际中的应用,并且介绍了几种可以提高 SQLite OLAP 场景下性能的方法。我主要有三点印象颇为深刻:
- 第一就是我们只需要一些简单的方法,譬如用布隆过滤器来减少 B-tree 的查询就可以非常明显的提高 OLAP 场景下的性能。换言之,找到性能的瓶颈之后,很多看似简单的方法实际上可以带好非常好的效果。
- 其次是 SQLite 尽管设计定位于传统的 OLTP 场景,但目前实际上也常常用于小文件的存储。但是 SQLite 在小文件上读写上的性能却不一定总是优秀的。这需要我们更多的探索和实验。
- 最后是怎样更好得提高 SQLite 在 OLAP 场景下的性能同时尽量减少或者完全不影响 OLTP 场景下的性能呢?目前一种流行的方法是在 SQLite 中另实现一个独立的、但能和 SQLite 本身相互的查询引擎。这个新的查询引擎中可以设计单独的针对分析型数据查询优化的功能。当前这种方法已经被 SQLite3/HE 使用。但更多的方法还需要进一步的研究和探索!