威尔·史密斯再次贡献了梗图,上回是奥斯卡的一巴掌,这回是意大利面的吃播。
2023 年 3 月,一位 Reddit 网友用 AI 制作了威尔·史密斯吃面的搞笑视频,面目狰狞,五官变形,看得人胃口全无。
2024 年 2 月,OpenAI 发布 Sora 的两天后,威尔·史密斯本尊在 Instagram 发布了一条吃面的对比视频,人变帅了,进食动作也体面了。

你以为下半部分的视频是由 Sora 生成的?不,面就是威尔·史密斯真人亲口吃的,整了个活而已。
前脚被 Sora 的官方演示震撼,后脚看到这条动态,人们陷入了我是谁、我从哪里来、我到哪里去的人生怀疑。
虽然 Sora 还没有对外开放,但互联网已经变得越来越荒谬了:AI 视频越来越接近真实,越来越多的真人视频却假冒 AI。
能不能杀死好莱坞不知道,Sora 先把我大脑干烧了
Sora 稳定发挥的视频,我们或多或少都看过了,同时 OpenAI 也把翻车视频大方发布出来,其中有些在社交媒体热度更高,尤其下面这个提示词是「考古学家在沙漠发现一把普通的塑料椅子,小心地挖掘并除尘」的视频。

椅子好像是个会呼吸、有想法的异世界生物,不被重力和人力无法束缚,凭空出现、变形,还偷偷带走了一个人类。这或许并非 AI 的错,毕竟提示词里没有写明,他们是否在地球上。
如果视频被分发到社交媒体,可能会打上这样的标签:#意识流、#超现实主义、#人类早期驯服野生椅子的珍贵视频……
OpenAI 认真地解释了为什么出现 bug:Sora 未能将椅子建模为刚性物体,即外力作用下不改变形状和体积的物体,所以导致物理交互不准确。
Sora 这个摔碎杯子的视频,仿佛也是吃了毒蘑菇才能看见的艺术,杯子竟然无风自动,液体先像果冻一样闪现玻璃才摔碎,每个步骤都在意料之外。

另外,还有倒着用跑步机的运动健将、怎么也吹不灭的生日蜡烛、凭空出现又消失的狼群……AI 在不经意间,做出了人脑和特效都想不到的事。

Sora 官宣以来,AI 大佬们就在争论它能否理解物理世界,OpenAI 的技术报告没有明确表态,只是提到,Sora 可以模拟现实世界中人、动物和环境的某些方面,但可能难以准确模拟复杂场景的物理原理,比如混淆左右、咬了饼干后没有咬痕。
趁 AI 还未进化到完全态,不妨脑洞大开。还不稳定的 AI 视频,完全可以作为灵异、悬疑、恐怖、幻想题材的素材库,为创作提供新的灵感,越要掀牛顿棺材板的,表现得就越艺术。
就像「挖掘椅子」和「摔碎杯子」,已经可以用到 MV、广告、电影、游戏里,看起来还是个大制作,效果纵然诡异,却意外得很丝滑,完胜 B 站「学了五年动画」系列。

尽管内容已经如此魔幻,还是有网友犹豫了一秒:「不露 bug,我都怀疑它是拍的。」「这是在玩魔术吗?」
这是因为,哪怕是 Sora 的翻车视频,时长、画质、稳定性也依然能够吊打 Pika、Runway 等「前辈」。
当其他工具生成的视频不过 3 到 4 秒、尽量保持单镜头稳定时,Sora 把上限拉到了 1 分钟,实现多镜头的无缝切换,相对准确地保持画面主体和视觉风格的一致,仿佛会用镜头语言和叙事节奏讲故事。
乍看之下,好像现场真的有摄像机跟拍,人、物体和场景都在三维空间里移动,同个角色还能有多个视角。

▲ Sora 可以实现多个视角.
有人开玩笑说,这是 AI 生成视频从「动图」到「视频」的飞跃。
翻车的 Sora 视频当然也可以算入其中,就像乱七八糟写了一堆代码,但恰好能运行。
360 董事长周鸿祎在微博谈到一个很有意思的观点:Sora 工作原理像人类的做梦,我们会梦到奇奇怪怪的东西,但依据的是我们在生活中眼睛看到的东西、积累的经验,不用像影视工业那样 3D 建模然后一帧帧地渲染。

从某个角度看,生成式 AI 确实像一个梦境机器,越来越接近人类的思维方式,用各种提示词有概率地制造合理或者不合理,不论对错,它一定会给你一个答案。
其实从 ChatGPT 开始,人们就想借着 AI 将梦境落地,小红书上有不少将梦境可视化的帖子,虽然无法真正还原脑海的效果,却也将部分精神世界的幻影带入了现实。
未来的 Sora,可能更让梦境或者说人类的创意生动起来,输入文本、图片或视频,就能「一键」加入光影变化、调整画面角度甚至配上音效……
好莱坞的精英会不会失业不知道,网友们已经跃跃欲试,除了搞黄色的本能,脑洞也有了安放之处。
自嘲一败涂地的人类,将模仿 Sora 当成流量密码
翻车视频之外,Sora 的其他视频乍见惊艳,但也经不住放大镜式的审视。店铺招牌的乱码、猫的第五条腿、模特踏错的步伐……

Bug 或许是 AI 和现实的最后一堵墙,但人类自己想把它推倒。
虽然 Sora 还没有开放给公众使用,但卖课和卖芯片的赚钱了,玩梗的乐子人们也找到了浑水摸鱼的办法,发明了一种新的引流方式。
他们在社交媒体发布视频时,往文案里加入「由 Sora 生成」和像模像样的提示词,伪装成是 AI 制作的,就像威尔·史密斯模仿 AI 如何模仿自己。

各个赛道的短视频博主都参与其中。晒萌宠的、打游戏的、安利偶像单曲的、给产品打广告的…… 真的不是给 Sora 提供就业灵感吗?

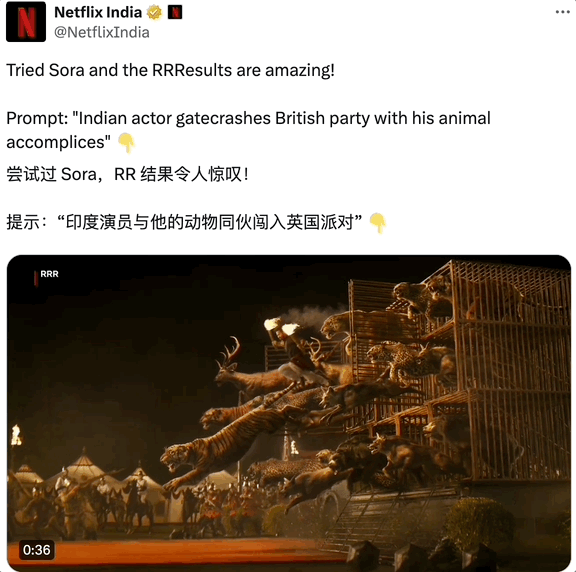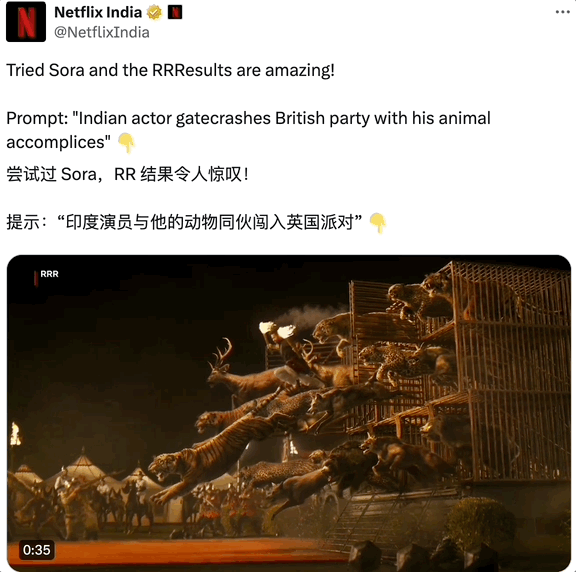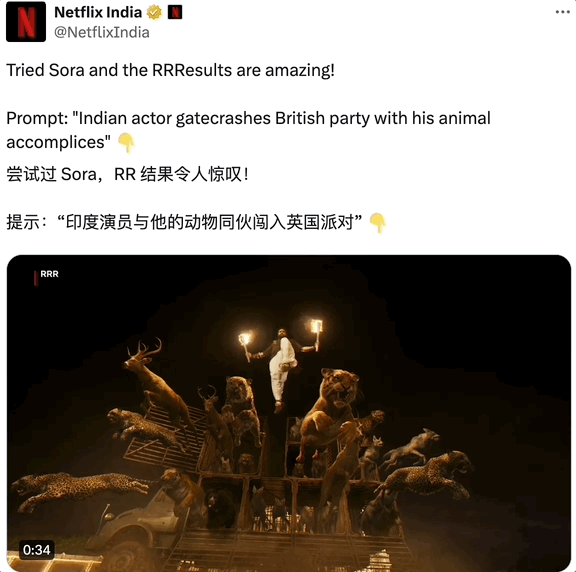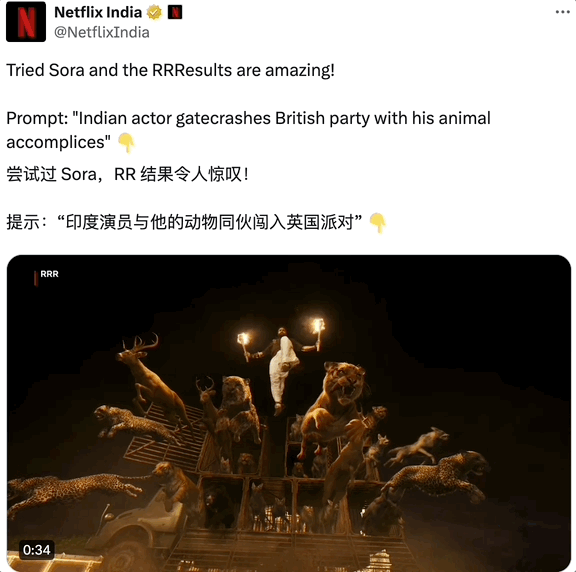
其中最让人真假难辨的当属宝莱坞电影,印度警匪片的情节和特效尤其惊人,对人类来说太超前了,也让物理学不存在了,连 AI 都要向他们拜师学艺。

如果不是热心群众添加注释,附上了 11 年前上传的 YouTube 链接证明印度电影非人的先锋性,谁也不敢打包票。
甚至 Netflix 印度官方账号也来凑热闹,从印度抗英神片《RRR》截取了个片段伪装是 Sora 生成,按照印度大片一贯的浮夸,头几秒确实可能会骗到观众。
这些假冒 AI 的视频固然由人类整活,AI 混在其中都显得平平无奇,但 AI 未必不能效仿。
混淆视听、自作自受,伤害还是人类自己,猜疑链已经出现了。
网友们开始担心,当 AI 生成和真人实拍真的傻傻分不清楚,自己没做过什么,却可能「证据确凿」。

这就是悬疑英剧《真相捕捉》上演的情节:情报机关为了给罪犯定罪,伪造了监控录像。
他们认为,伪造监控录像,只是将窃听材料等非法证据,「重演」为合法证据,事情的确发生了,罪犯的确犯罪了。

但是谁也不知道,使用技术的人会不会越界,从移花接木走向无中生有。
辨别 AI 的应对之法,也可能换个角度,用来当作金蝉脱壳的妙计。
因为 AI 不擅长画手,所以之前有个梗图是,犯罪分子戴着假手指犯罪,看起来有六根手指,就可以污蔑监控录像是 AI 生成、没法作为呈堂证供。

AI 接近现实,同时人类假冒 AI。AI 伪造呈堂证供,也能被利用让证据无效。一个魔法打败魔法的魔幻世界,可能真的要到来了。AI 还没法主动作乱,打破信任的还得是人类自己。
AI 还未必能模拟世界,但已经影响了我们看待世界的方式
关于 AI 让真实与虚假更难分辨的问题,当我们说到 Deepfake 换脸时,其实已经讨论太多了。Sora 又能有什么不一样?
最近,OpenAI 做了一个意想不到的举动——开设 TikTok 账号,上传 Sora 的作品。
OpenAI 不仅为每个视频贴心地标注了 AI 生成,怕人们混淆现实,还附上了提示词。

「一段逼真的视频,展示了一只可以在水下游过美丽珊瑚礁的蝴蝶」「一片叶子的微距拍摄,显示微小的火车在叶脉中移动」「低至地面的摄像机密切跟踪丛林中的蚂蚁」……

这些视频混迹在真实的短视频信息流中,配上了背景音乐,如果稍微不注意,手指滑得快了些,就可能被认为是真实的。
网友们半开玩笑半认真地在 OpenAI 评论区嘱咐:「你最好制作水印之类的东西,否则人类就注定要灭亡。」
Sora 还没落地,其实所有人都在猜测,视频内容从业者可能是最淡定的一批人,因为他们更加专业,也更懂商业化,Sora 的 Demo 一堆问题,内容的一致性和准确性不够,做不到甲方精细的要求,技术就很难被引入工业流程。
但我不是很乐观,AI 影响的早已不只是真假,而是我们看待世界的方式,它并非直接代劳某个剪辑软件、某个脚本、某个导演。
AI 从业者 @Kwebbelkop 猜测,OpenAI 目前只在 TikTok 发布 AI 短视频,可能是为了收集观看次数等相关用户数据,对模型进行来自人类反馈的微调,未来甚至再造一个 AI 版 TikTok。
短视频的算法已经非常能猜你喜欢了,如果再加上生成式 AI,让视频内容更加定制化,又会发生什么?
未来,我们的观影体验也可能发生质的变化,不依赖于电影院和流媒体,可以用大语言模型和视频生成模型决定故事内容和主演阵容。

然而,OpenAI 对 AI 产品的期待绝对不只是陪你聊天、制作视频,更深入的野心是让 AI 学习人类的自然语言和世界的物理规律。
哪怕局限在视频领域,就让 Sora 能做粗糙的概念片,也已经很厉害了。制作视频的方式、内容的风格,甚至我们对内容的喜好,或许都将因为 AI 而发生改变。
先不说 AI,几乎人人持有的手机,其实已经影响了视频的拍摄和制作方式,让人人成为自己生活的导演。
对着镜头边说话边化妆的美妆视频、展现个人生活碎片的 Vlog 等,就是在这种影响之下,很多博主在卧室用手机就能拍摄的产物。短视频的井喷,也让我们越来越习惯用手机上下滑动,耐心更少,注意力更分散。
尽管相比 Sora,Runway、Pika 等视频生成工具能力有限,也已经有人结合 Midjourney 等图片生成工具,用它们做了电影预告。
因为稳定性较差,所以视频风格也有了取舍,以快速剪辑为主,搭配旁白,注重节奏感和视觉冲击,但缺少人物的对话和更复杂的场景。

▲ AI 科幻短片《Borrowing Time》.
相比之下,Sora 可以支持更复杂的场景、角色动作以及角色和周围世界之间的交互。有人用 Sora 的样片,再用 AI 语音工具 ElevenLabs 配音、用 iMovie 剪辑,就做出了一个更加流畅的、仿佛「一镜到底」的「电影预告」。

Sora 对外展示的两类视频,大概可以分为两种,一类是创意脑洞,宇航员站在寒冷的星球、两艘海盗船在咖啡中决斗、卡通人物跳迪斯科,一类是接近现实,淘金热时期的加州、火车车窗上的倒影、2056 年尼日利亚的户外……

火车车窗上的倒影,很像 Vlog 会拍摄的镜头。尼日利亚的户外,镜头从露天市场平移到城市景观,也非常像新闻视频的空镜,已经有人打算将数字人和这条视频结合。

拍摄甚至在有些时候显得没有必要了。Sora 可以通过提示词,直接制作某个旅游景点的鸟瞰图,和人类飞无人机的镜头相差不远。我们的眼睛和大脑知道圣托里尼岛长什么样,AI 同样也「知道」,那么就可以交给 AI 代劳。

之前有个很有意思的比喻,这个世界就是个巨大的「地球 online」,由太阳系开发的大型多人在线角色扮演游戏,拥有最优秀的 3D 裸眼和 VR 系统。
OpenAI 提出的「世界模拟器」的概念,某种程度上是把一切当作信息输入,汲取着文字、图像、视频,然后又输出信息,把文字变成绘画,把图片变成视频,仿佛「地球 online」的主宰,但我们未必了解其中的原理,可能只是给出要求,然后得到结果。

这样的未来应该还很远,至少眼下,Sora 的视频看多了,也会让人觉得无聊,走在东京街头的女性,眼睛里没有情感,感受不到人的气息,但我们刷短视频时有时也是这样,世界需要精妙的电影,也接受巨大的冗余,就像《黑客帝国》主角的反抗也是设计好的。
AI 参与感越来越强的未来将要到来。下次看到一个疑似的 bug,我们可能不会直接判断是假的,我们或许像做阅读理解一样想,AI 在这里是不是有什么用意。我们也许不会喜欢,但不得不接受。