答案是在特定任务上可以的。
之前的答主们已经把一些相关工作介绍了,但是基本现有的工作都是集中于reasoing task,我们目前最新的工作在此基础上做了一系列的改进。
我们组关于针对 gpt3.5等ChatGPT背后的模型窃取(Model imitation attack/ Model extraction attack)的一些研究成果,目前我们已经将文章开源到了arvix上,大家有兴趣的可以访问, 简单来讲,我们首次对在黑盒条件下的大模型窃取做了一系列的研究,发现通过较小模型可以在特定代码相关的任务上逼近甚至超过大模型的能力。
我们研究的意义在于:我们指出了用中等规模的模型去部分窃取大模型在特定任务上的性能是可行的,为无法承担训练超大模型的公司/个人提供了解决方案,同时也对未来模型保护提供了一些见解。
写在前面
为啥要做chatgpt的模型窃取?
原因有二:
- OpenAI 并没有开源自己的模型。 作为OpenAI的 知识产权,这是他们能向公众收费的基石,但是同时也让这件事看上去没有那么公平。
- 大模型的训练成本已经达到了无法承担的地步。 几百张,几千张卡对于大部分中小公司和个人来讲,都是可望而不可即的。
为啥模型窃取能够奏效?
众所周知,OpenAI在三月初开放了新的API(gpt-3.5-turbo),和原有的davinci 系列成本仅仅为原来的1/10. 然而其模型效果,这里引用官方说法是 "几乎差不多"。 这说明在知道其内部细节的情况下,对模型进行剪枝/压缩/裁剪 是完全可行的。另外更多的说明可以参考我们论文的引用。
正文
背景介绍
大模型(Large language models)
原文讲了很多,我们这里主要介绍下两种范式和模型的突变能力(emergent ability)
两种范式 分别是 pretrain-finetune 以及 pretrain prompt
pretrain finetune 模式是指在一个大型数据集上进行预训练,然后在一个小型任务上进行微调。这种方法的优点是可以利用大量数据进行训练,从而学习到更加通用的特征表示,同时又可以在小型任务上进行微调,以适应具体的应用场景。pretrain prmopt 模式是指在一个大型文本数据集上进行预训练,然后通过给定的 prompt 来生成文本。这种方法的优点是可以直接生成符合要求的文本,并且可以通过修改 prompt 来控制生成的文本的风格和内容。两种方法的区别在于 pretrain finetune 模式主要用于分类、回归等任务,而 pretrain prmopt 模式主要用于生成文本。同时 pretrain finetune 模式会产生一个能够直接解决具体任务的模型,而 pretrain prmopt 模式则主要用于生成文本。 以往以Bert为代表的都是pretrain finetune 模式, 而GPT3等大模型都是pretrain prompt模式。
突变能力 研究发现 随着模型size的增加,模型的理解上下文能力也相应的增加了。
以wei等人从2022年开始的一系列研究表明=> 1. 模型大到一定程度以后,其理解能力以及在各个方面的能力都有巨大的提升[1]
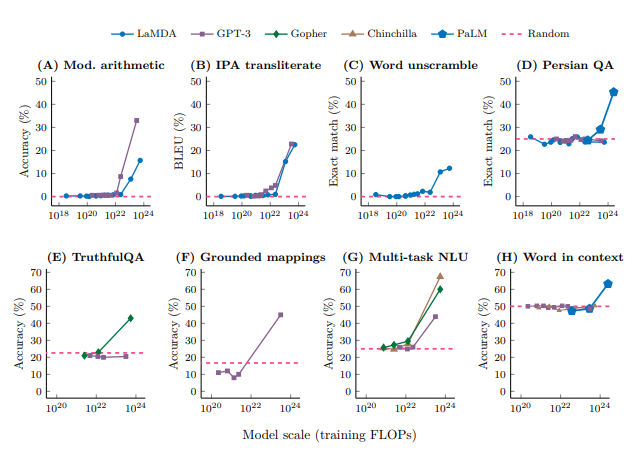
思维链(CoT)
关于思维链,知乎上已经有许多优秀的回答了,例如 思维链 知乎
Yao Fu [2] 总结了四种思维链的形式,我这里简单借用下

模型窃取攻击
模型窃取攻击作为近些年的热点问题,也可以分为两类:
- 灰盒攻击 这种攻击往往有预先的假定, 例如数据的分布情况,模型的架构等等
- 黑盒攻击 攻击者什么都不知道
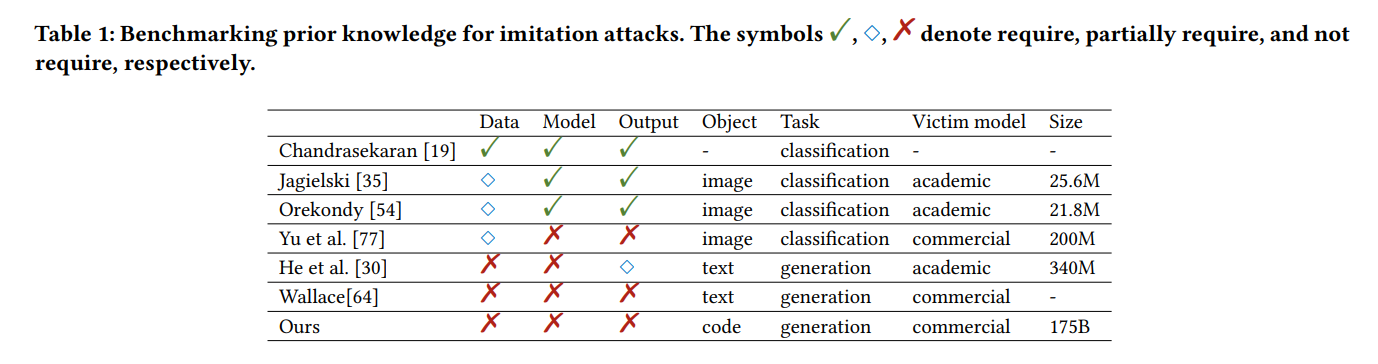
以往的工作和我们主要有以下三点不同:
- 窃取对象不同: 我们专注于用中等规模的模型去窃取大模型的部分能力,而大部分工作的victim和imitation model是相近规模的
- 任务不同:以往工作[3,4]往往关注图像分类等分类任务,针对生成任务的仅有机器翻译以及reasoning tasks
- 攻击假设前提不同: 如上文所说,我们不会假定攻击者有任何Prior知识
我们思考一下Chatgpt给我们的回复,就可以发现由于采用了Machine-Learning-as-a-Service (MLaaS),我们是没办法拿到任何和模型有关的内容的,所以黑盒攻击就成了唯一的选项。
攻击目标
我们选取了代码总结,代码翻译,代码生成三种任务来进行研究。
我们希望我们的攻击能达到如下效果:
- 通过窃取到的中等模型在任务表现上 接近或者超过 原有大模型
- 窃取的成本要在可控的合理范围内
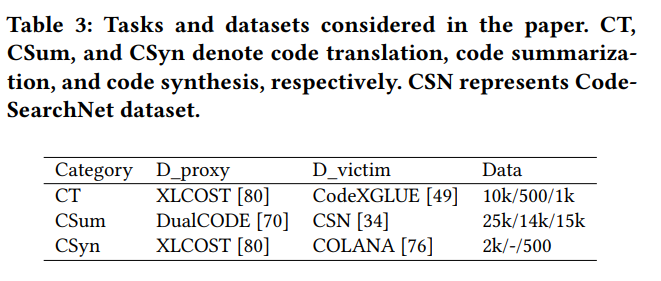
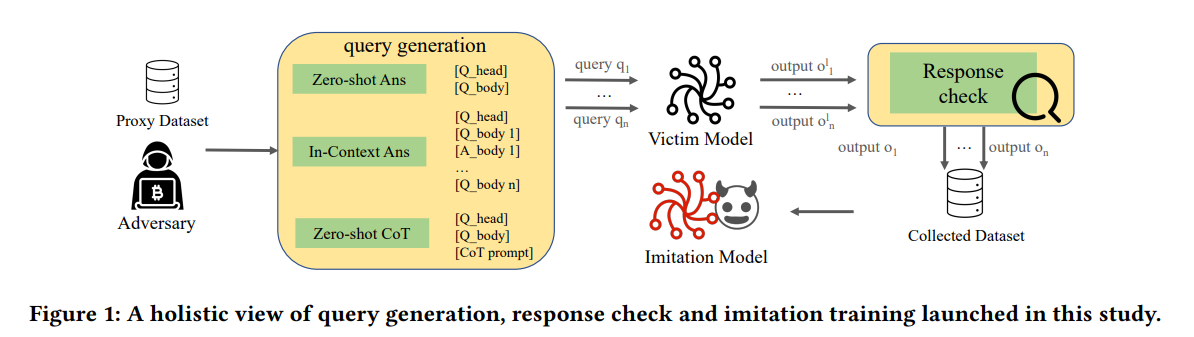
攻击方法
结合上文所讲,我们这里设计了3种不同的query 方式, 分别是 zero-shot/ in-context / zero-shot CoT,
并且结合了不同的筛选方法和训练方法,完成了对于chatgpt在 特定任务上的窃取。
实验结果
我们设计了如下四个问题来帮助我们理解模型窃取
- 问题1:在代码相关的任务中,模型窃取攻击的效果如何?
- 问题2:不同的prompt策略和窃取方法的选择如何影响性能?
- 问题3:应该用多少次query来完成模型窃取?
- 问题4:超参数如何影响攻击的性能?
问题1:在代码相关的任务中,模型窃取攻击的效果如何?
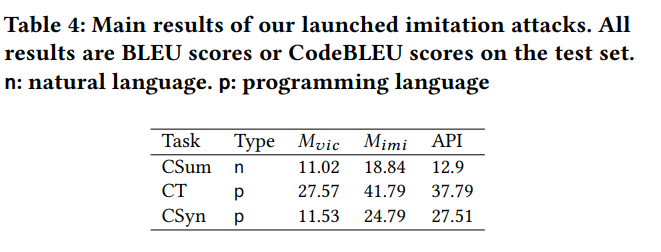
我们表明 通过窃取到的中等模型在任务表现上 接近(CSyn)或者超过了(CSum,CT) 原有大模型。
问题2:不同的prompt策略和窃取方法的选择如何影响性能?
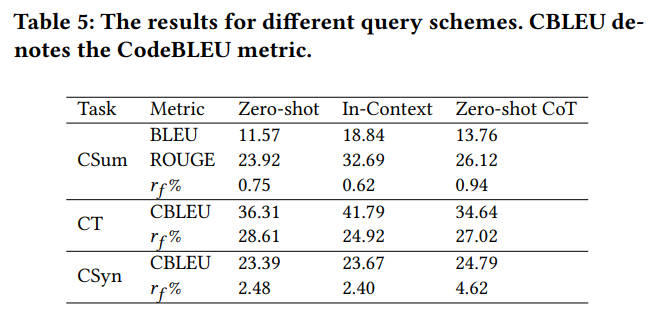
通过对比我们发现
- 思维链在生成自然语言的任务上比较有用,在其他任务上作用很小,同时还可能导致生成的代码质量迅速下降
2. 提供合适的上下文仍然是显著提高效果的好办法
问题3与问题4 由于涉及到太多的细节,我这里就不细讲了,把结论贴出来:
在相同的训练能力下,窃取模型的性能超过了baseline,并随着query次数的增加而不断提高。然而,攻击者需要平衡成本和性能,以避免边际效应。 OpenAI采样超参数对查询结果没有太大影响,重要的是query的数量。我们建议在上下文学习中使用三个例子,以保持其在合理成本下的有效性。
一些声明
- 目前我们只放出了少量的结果,关于如何在更多的NLP 任务上进行窃取,以及如何提高窃取的性能和效率,我们暂时没有囊括到本文中。
2. 该技术仅仅用于学术研究,相关人员没有用所得到的模型进行任何形式的盈利。
3. 所有对OpenAI相关API的访问均符合法律法规。
[1] Wei, Jason, et al. "Emergent abilities of large language models."arXiv preprint arXiv:2206.07682(2022).
[2] Fu, Yao, et al. "Specializing Smaller Language Models towards Multi-Step Reasoning."arXiv preprint arXiv:2301.12726(2023).
[3] Wallace, Eric, Mitchell Stern, and Dawn Song. "Imitation attacks and defenses for black-box machine translation systems."arXiv preprint arXiv:2004.15015(2020).
[4] Orekondy, Tribhuvanesh, Bernt Schiele, and Mario Fritz. "Knockoff nets: Stealing functionality of black-box models."Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.