
AMD昨天午夜时分在Together We Advance Gaming发布会上正式宣布了自己的新一代GPU架构RDNA3,并公布了首发产品Radeon RX 7900XTX以及Radeon RX 7900XT。RDNA3其实是一个非常有趣的产品,我没选择当天写简评是因为AMD突如其来的Zen4降价,让我得重新评估AMD的RNDA3的定价策略,从而去判断RDNA3的产品力。关于这个产品力,我们留到最后再来说吧。
Chiplets设计
胶水思路
为什么说AMD的RDNA3是一个有趣的产品呢,这就离不开其独特的Chiplets胶水设计了。

相信经过了AMD Ryzen系列的科普后,我们都知道做胶水Chiplets的主要动机是降低成本。AMD无论在CPU领域还是GPU领域,都处于出货的弱势区间,在靠产量摊薄成本上远不如Nvidia和Intel来的厉害,如何尽可能降低成本以保证竞争力是AMD一直需要考虑的事情,也正因如此AMD在RDNA3上引入胶水设计是那么合情合理。
胶水Chiplets设计在CPU领域已经有一段发展历史了,比如其实最早的Intel Pentium D就是胶水双核。但是在GPU领域,Chiplets设计是到近几年才出现的,并没有真正的普及开来。不计算Intel Xe-HP那种实验室里就被扼杀的产物,在RDNA3之前的胶水设计其实只有Intel的Ponte Vecchio以及AMD自己的CDNA2.
为什么在CPU领域那么常见的胶水设计,却迟迟不出现在GPU领域呢?其实核心原因在于,相对于GPU而言,CPU并不是计算密集的设备,所需要的互联/内存带宽本身是显著低于GPU的。GPU是计算密集的设备,其对带宽的要求远高于CPU,比如高端的各类GPU都需要TB/s级别的显存,而CPU只能到数百级别的内存。也正因此,在胶水互联的技术上,GPU的Chiplets设计要求的互联技术是远高于CPU的。也正因为对互联高的要求,现在的三个常见的Chiplets GPU(CDNA2、RDNA3、以及Ponte Vecchio)里,有且仅有Intel的Ponte Vecchio可以说是真正的Chiplets GPU
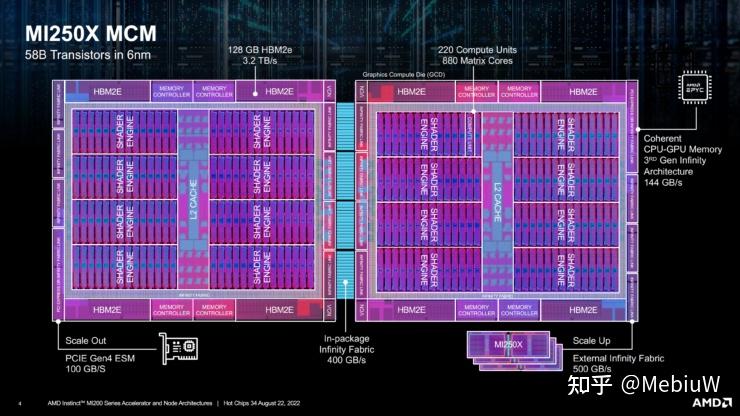
我们首先来看AMD自己的CDNA2,最高端的MI250X MCM是有两块核心,通过400GB/s的Infinity Fabric进行互联。 这里的Infinity Fabric MCM 胶水,其提供的400GB/s宽带是非常有限的,远不如2.5D CoWoS链接的HBM的带宽。 你想,两块GCD的互联需求是很高的(有兴趣可以算算GPU内部的带宽需求),但是这个Infinity Fabric胶水带宽连HBM都不如,你不能指望真的能把他们链接起来。 之前分析CDNA2的时候,也有粉丝指出在操作系统内MI250X CNDA2是被当做两块GPU进行调度,而不是一块。 所以CDNA2胶水的意义,其实只是提升物理上部署多GPU核心的密度,并且提升2个GPU之间的链接能效的。CDNA2在逻辑上,依然还是两个GPU。

我们回到最新的RDNA3上,可以看到AMD这里的思路和CDNA2是完全不同的。RDNA3是有一个计算核心GCD,搭配N个访存MCD。 所以RDNA3的计算核心部分是没有胶水化的,完全走in die的fabric,从根本上避免了互联带宽的问题。 RDNA3的胶水化只是将显存控制器以及Infinity Cache拆分到了MCD上,这一方面因为先进工艺对于MCD这种模拟电路和SRAM为主的芯片没什么提升性价比低,另一方面是这二者都是有大量重复的。

现在的封装技术,用于解决MCD所需的带宽是比较容易的。AMD自己给的例子是,RDNA3的这个MCD*6共计能够提供5.3TB/s的峰值带宽,大概也就是每个MCD 900GB/s不到的带宽,这对于走硅中介的2.5D封装技术来说是比较容易达到的。AMD的RDNA3具体走了什么封装我不太清楚,Anandtech本来说走了Elevated Fanout Bridge (EFB),但是后面又划掉了,所以实际是什么还有待考证。但是从之前泄露的一张实物图来说,我觉得还是比较像走了CoWoS的,很明显看得到GCD和MCD下方有一个硅片中介。

最后我们再来看看,为什么我说Intel的Ponte Vecchio才是真正的胶水GPU。因为Ponte Vecchio在计算部分(类比GCD)和存储部分(类比MCD)都是完全Chiplets化的,其通过大量的2.5D和3D进行互联,并且这些芯片在逻辑上是一个整体,只是物理上的胶水(当然你看到的Ponte Vecchio实际上也类似CNDA2,再做了一次两个区域的简单互联,我说的逻辑上统一是你单独看左边一半或者右边一半)。 反正胶水狂魔Ponte Vecchio基本上什么互联都有了,大家要好好学习领悟。

成本
通常来说,胶水设计之所以能降低成本,其主要得益于:1)更小的芯片良率更高成本更低。2)通过大量复用降低成本。3)不同芯片用不同工艺。 RDNA3拆分了MCD并采用了6nm制造,所以完美享受了上述1)2)3)的优势。
一个6nm MCD面积37mm2,如果采用5nm制造并集成在GCD中,那么因为IO电路和SRAM的限制,估计也要占用20多mm2,会直接让GCD的面积到400mm2多。而现在拆分后,可以显著降低GCD的成本,用更便宜的工艺,并且MCD因为复用程度很高,不但现在的Navi 31受益,之后的Navi 32也可以受益,一个设计吃遍。
但需要说明的一个事情是,胶水设计降低的是每个部分的制造成本,但是胶水设计在封装时也会引入新的成本。 对于Navi 31来说,GCD+MCD的总计面积是300+222=522,可能还有一个硅中阶层(如果这个方案 这个肯定大于522,可能会在600-700)之间。
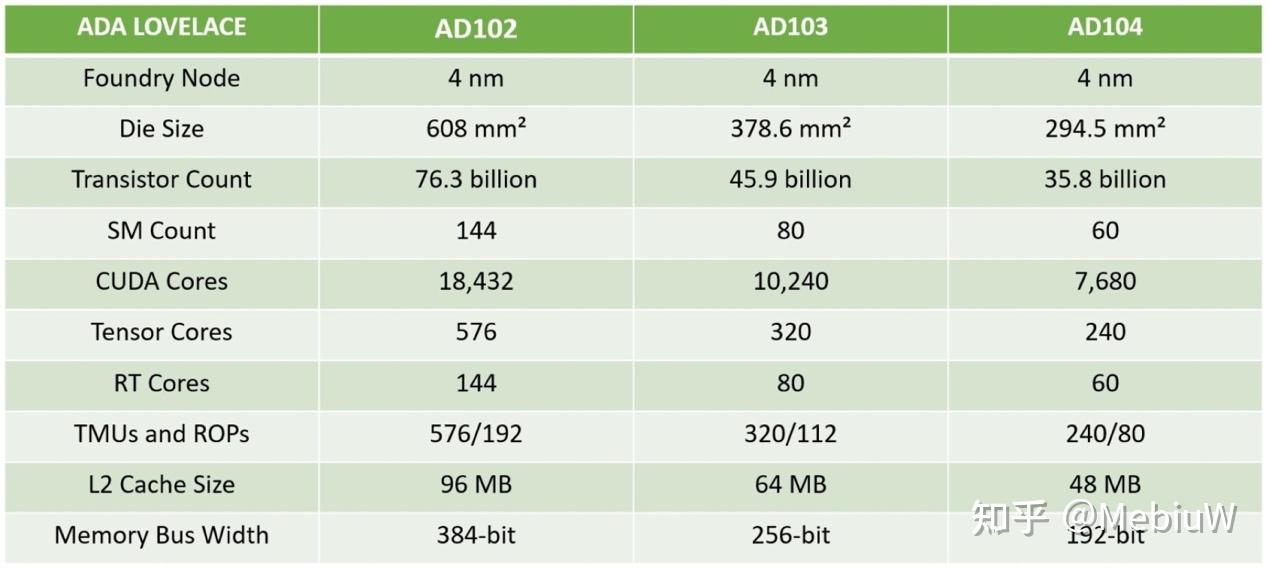
那么目前首发的RDNA3对位的应该是哪一个Nvidia的Ada Lovelace卡呢?Ada Lovelace采用4N工艺,实际上也是N5工艺,并不是N4的衍生。我们可以看到AD103的面积是378mm2,和Navi31的300mm2 GCD最为接近。所以Navi 31的GCD成本肯定是显著低于AD103的,但是因为还有6个37mm2的MCD以及封装成本,AD103的成本应该是要低于AMD Navi 31的总成的。Navi 31的总体成本应该是高于AD103,但是低于AD102的。

RDNA3的旗舰版24GB 7900XTX定价是999美元,显著低于AD103的RTX4080 16GB的1199美元。 从物料成本上来说,AMD的定价是极度良心的,更高的成本,更低的售价。 反正落后就要挨打,我们最后说吧。
所以最后做个总结就是,从成本上来判断,RDNA3 Navi 31的成本在AD102和AD103之间,如果RDNA3的竞争力足够,那么售价应该至少不低于RTX4080 16GB。此外,如果RDNA3采用的是CoWoS,那么中阶层也需要进行光刻的,也会存在尺寸限制。CoWoS的极限可以到至少1000+mm2,但是我估计AMD不会用那么先进的CoWoS,估计还是700-800的某一代,所以估计难以看到更高规格的RDNA3。封装技术可能限制了RDNA3的规模上限。
架构
聊完了RDNA3最有意思的胶水设计,我们回归RDNA3的架构设计部分,看看这代到底改进了多少。
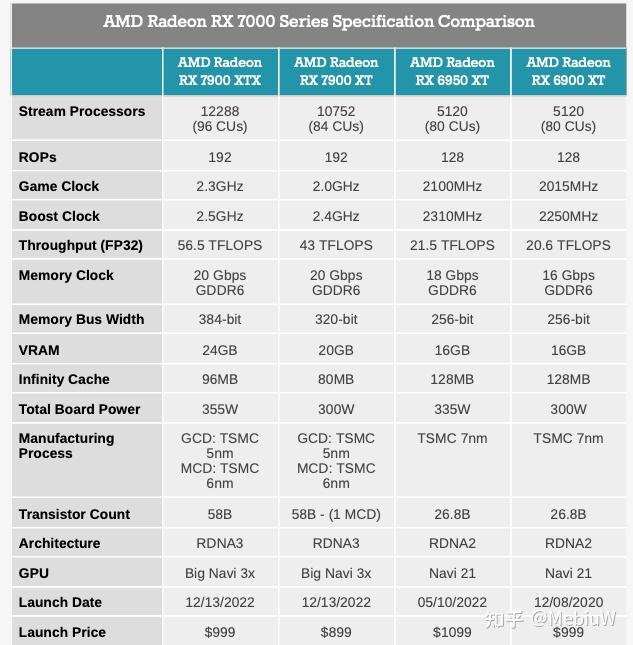
我们首先从核心参数上可以看出来,AMD RDNA3也引入了Nvidia从Ampere开始就有的双倍FP32设计,导致这回Stream Processor大增,FP32理论值也大正。但是这个设计更多是服务于特定计算,对于游戏和大部分任务而言,这个双倍的FP32,实际要乘上0.55-0.6才能和传统设计对比,这个很多采用类似思路的N卡、以及Apple A15 A16都验证了。所以千万别用采用了类似方案的GPU,直接通过FP32去判断性能。

7900XTX总计的最高FP32是61Tflops,应该是显著不如RTX4090的。基于经验主义,7900XTX算力大约是6950XT的3倍,乘上0.55-0.6的系数,7900XTX的实际算力应该是6950XT的1.6-1.8倍,我个人倾向于认为是0.55,也就是性能是1.6倍。另外7900XTX的GDDR6带宽大约提升到1.67倍,Infinity Cache速度提升,但是Infinity Cache容量减小,所以从带宽上看7900XTX的实际提升应该也大约落在这个幅度上。 AMD RDNA3并没有太多关于显存压缩的新技术,所以推断的可靠性并不会太差。

RDNA之前最大的软肋之一就是Matrix/Tensor引擎加速深度学习,Intel和Nvidia都是早早配备的,RDNA2只有一个Vector引擎。AMD这回在每个CU上配备了两个新的独立AI加速器(估计还是Vector),就可以看成是对此的改进。 RDNA3每个CU配备了两个独立的AI加速器,最高带来2.7倍的性能提升。

怎么说呢,这是一个很不错的改进,但是远不够。我就不拿Nvidia出来说了,那个不但Tensor 暴强还有Transformer Engine,连Intel的Xe HPG的Matrix 引擎都有至少4倍的速度提升(4倍的宽度)。RDNA3 大概率就是Vector 的数量翻倍,增加BFloat16,依然是没有实质的Matrix引擎。


而且我要泼一个冷水,你们看AMD的这个AI引擎是CU对CU的性能提升,RDNA3的规模增加主要来自于CU内ALU双倍issue翻倍的,所以实际上7900XTX对比6950XT只增加了20%的CU。所以这个2.7X的CU提升实际上,并不能叠加太多ALU数目的规模优势。而且AMD的2.7倍似乎是在BFloat16上测试的,RDNA2本身不支持BFloat16,那么可能是RDNA3 的BF16对比RDNA2的FP32,那么实际上的宽度可能只有1.35倍提升。 不太清楚AMD的这个AI 指令集支持什么,Intel都至少支持INT8 INT4/2什么的,能在低精度下带来不止4倍的提升。(补充一点,回过来审稿的时候发现,2.7X也没明说是每个CU的,如果是整体2.7X提升,那么实际上AI配比最多提升2倍,毕竟总体性能缩放值就是1.6-1.7X附近)。

RDNA2的另一个不足是光追性能差,从光追前和光追后的性能对比来看,AMD的RDNA2是落后Nvidia和Intel的(我说的是光追折损,而不是绝对性能,注意勿喷)。RDNA3增强了光追,但是依然和AI性能的提升类似,虽然名义上每个CU提升了1.5倍性能,但考虑到实际只增加了20%的CU,所以光追的性能增强和光栅性能的增幅都是1.7倍附近。 再换句话就是,RDNA3的光追资源配比维持在RDNA2附近,实际打开光追后性能折损估计差不多。不过好消息是,Ada Lovelace的也是类似情况,所以这项改进不好不坏吧。
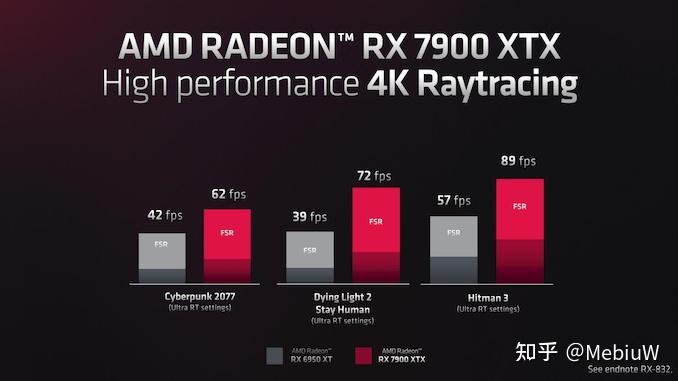
从实际情况来看,7900XTX的光追游戏提升在47%-84%附近,反正也就是刚刚说的光栅提升比例,就那样了。

RDNA3最后一项架构上的改进就是GCD的频率域进行了解耦,Shader频率(理解成Stream Core的频率)是相对更低的,而前端(Front-end)是相对更高的。这么做的前提是后面执行单元Stream Core的规模是高于前端的极限,前端成了瓶颈,进行分离后,规模更大的Stream Core可以降低频率,实现和前端的性能匹配,并降低功耗。这个设计是在前后端性能不匹配的情况下的好设计,但如果前后端匹配,也就没存在必要了。
不过话说回来,如果两个频率域能根据实时需求动态调整各自的频率,那额在前后端规模大致匹配的情况下也有用,毕竟不同场景需求不同,匹配与否都只是大致估算的。
软件

在软件部分,AMD本次推出了FSR3.0技术和Hyper-RX技术,这个基本就是对应Nvidia的DLSS3.0和Reflect技术了。FSR3.0同样引入了基于光流的插帧技术,然后因为插帧会引起延迟增加,又补偿性地加入了Hyper-RX来降低延迟。

不过我们之前也说过,AMD在深度学习加速的部分是比较孱弱的,也似乎没有专用的光流单元,AMD的FSR3技术是怎么做到的还有待考证。个人感觉不大可能完全类似DLSS 3.0,因为RDNA3硬件上先天就有缺失。
外围
相对来说RDNA3的外围增强就比较显著了,RDNA的视频编码解码部分有很大提升。这回采用了双媒体引擎,能效1.8倍,已经可以实现AV1编码的编码和解码了,持平Nvidia和Intel的最新GPU。AV1的具体编码解码性能都是8K60P,


在接口上同样显著,RDNA3支持DP2.1,从而带来了巨大的带宽提升,8K165 4K480不是问题了,Nvidia那边的DP1.4不知道是否硬件2.1,可能通过BIOS更新么? Intel的Xe-HPG是支持DP2.0。 反正现在RDNA3就是强。


总结
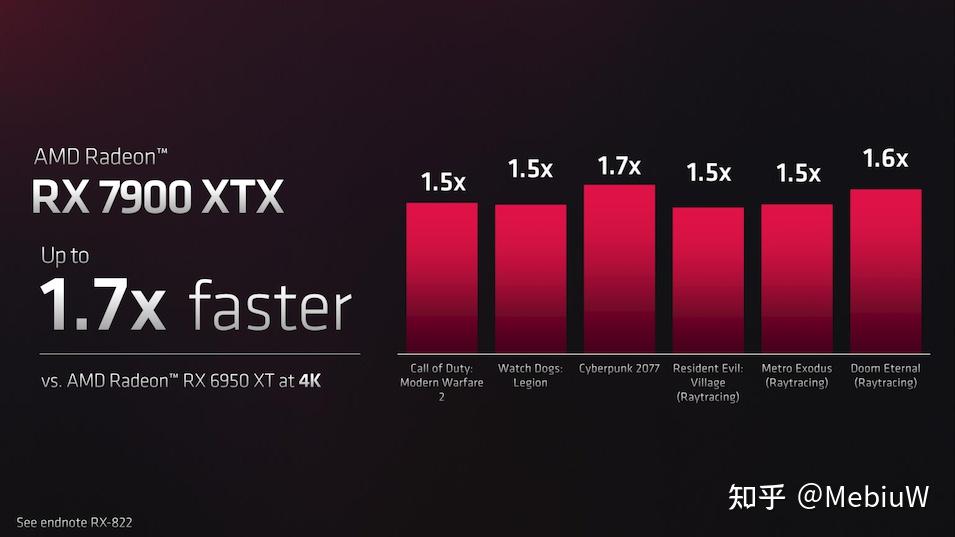
前面我们说过RDNA3的理论性能提升在1.6-1.8或者大致附近,AMD给的PPT多数1.5X,最高1.7X。但AMD另一个PPT很有意思,RDNA3的能耗比宣称提升54%,而7900XTX和是6950XT的1.06倍TDP,最终性能计算得到1.63倍。或许对于7950XT而言,平均而言,大概实际性能提升幅度也就是1.63倍吧,甚至不到。我觉得这个能耗比的1.63X可能会比较准确。
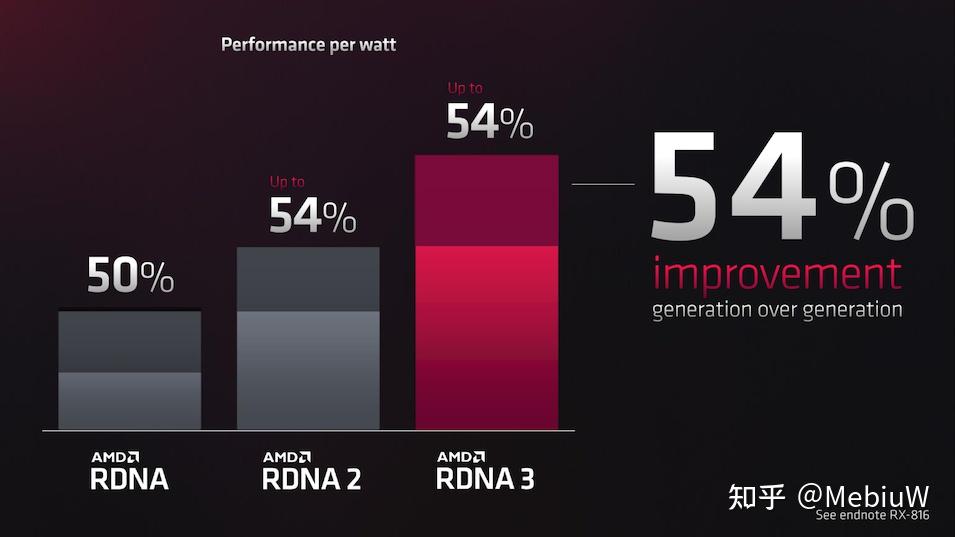
从AMD最终的定价来看,我对7900XTX的总体性能预期是在RTX4080 16GB附近算及格。 AMD近年来采用台积电先进工艺,带来性能优势的同时也带来了成本的提升。Navi 31的成本并不比AD103的4080 16GB低多少,AMD如果性能真的很强劲,不太可能定明显太低的售价。 就算是刚刚降价的Zen4,除了利润空间充分的7950X,AMD的CPU对比Intel同档也没有太多性价比优势可言,只是把产品放在了相对正确的价格上。

7900XT本身的光栅游戏性能体验可能并不差,就像当初RDNA2一样。但是我也说过DLSS的技术体系虽然复杂初期效果一般,但是上限很高,而不太依赖深度学习的FSR的上限并不高。今年DLSS3.0真的成熟很多,也是Ada Lovelace的一个主要卖点,RDNA3在光追、光流、深度学习依旧全面落后的前提下,FSR3.0到底能做到多好,我是表示怀疑的。 评测的时候可能可以不开DLSS3之类比,但实际有多少玩家能拒绝DLSS3的诱惑呢?
另外,再说一个Intel的东西。 AMD的核心设计能力比Intel好很多,但是Intel在深度学习、光追上给的料是看齐Nvidia的,有时候我也难以说到底谁是对的。 AMD不堆这些东西是因为设计能力不如Nvidia,所以要把钱花在主菜上,有利于成本控制。Intel设计能力更差,但是在配菜上给的很足,成本巨高,但是消费者不买账啊。
推荐阅读:
MebiuW:【急就章】AMD RDNA2 Radeon 6800系列速评: 终于再次重返巅峰 Maxwell黑科技解锁?
MebiuW:简评:Nvidia RTX40系显卡 Ada Lovelace
MebiuW:速评英特尔首个“独显”:ARC锐炫、代号Alchemist、 Xe-HPG架构
MebiuW:速评Nvidia最新4nm Hopper架构计算卡核弹H100